مساله ای که معمولا در استفاده از تنسورفلو و حتی تیانو وجود دارد این است که ما نمی دانیم این دو دقیقا دقیقا چه هستند! مساله ای که معمولا مارا مجبور به استفاده ار ابزارهای سطح بالاتر مثل کراس می کند. این کتابخانه ها خودشان را به عنوان ابزارهایی برای پیاده سازی الگوریتم های یادگیری عمیق معرفی کردند. اما درواقع مفاهیم پشت صحنه این دو ابزار مفاهیمی مستقل از یادگیری عمیق است. مفهومی که در عین سادگی پیچیده ترین ساختارهای محاسباتی را برای ما تولید می کند. گراف محاسباتی۱ مفهوم پایه برای این دو ابزار قدرتمند است. گراف محاسباتی شبیه درخت های پیشوندی و پسوندی(برای عملیات ریاضی) است با این تفاوت که الزاما ساختار به صورت درخت نیست. مثلا عبارت های زیر در نظر بگیرید:
c = a + b
d = b + 1
e = c * d
گراف محاسباتی برای این عبارات به شکل زیر است:
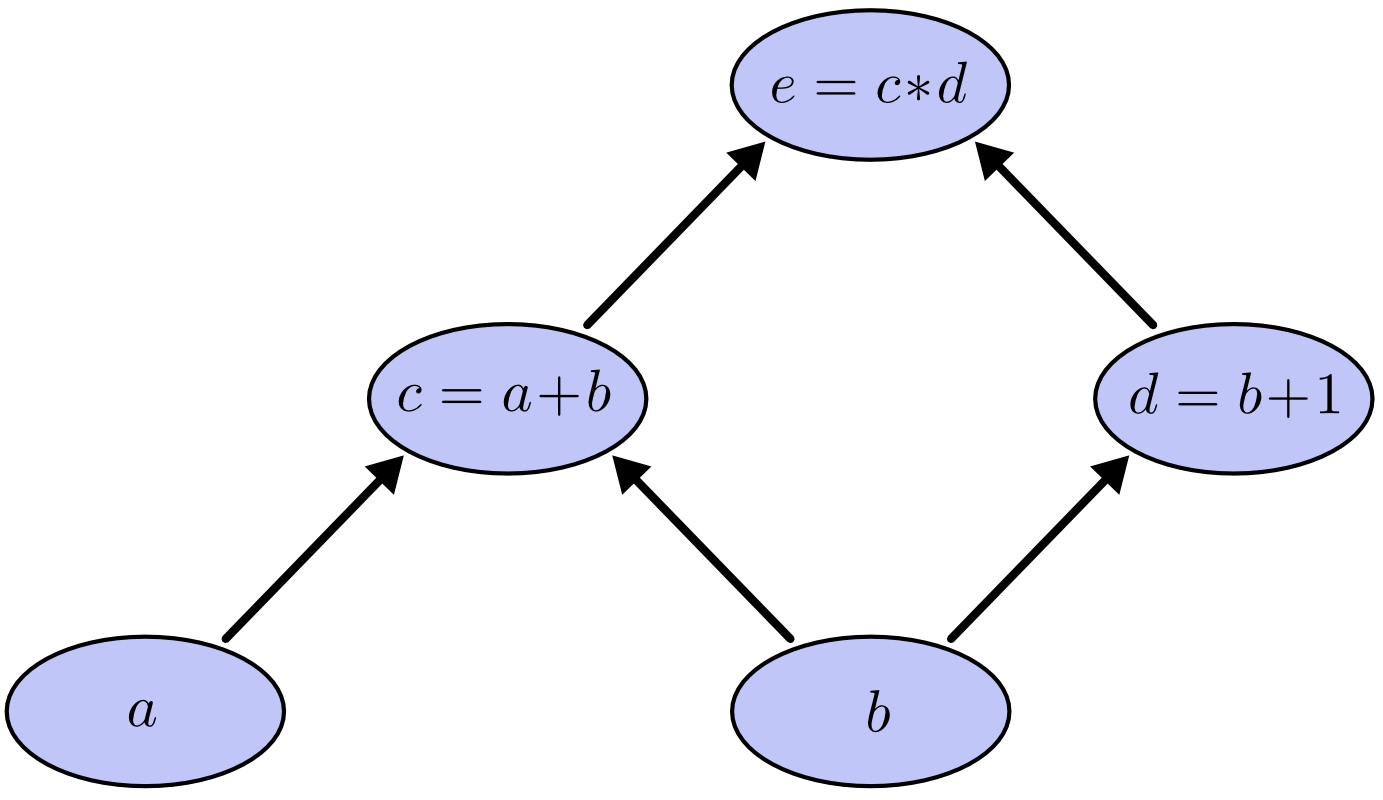
اگر مقدار a برابر ۲ و مقدار b برابر ۱ باشد گراف محاسباتی به صورت زیر در می آید که مقدار عبارت نهایی برابر ۶ می شود.
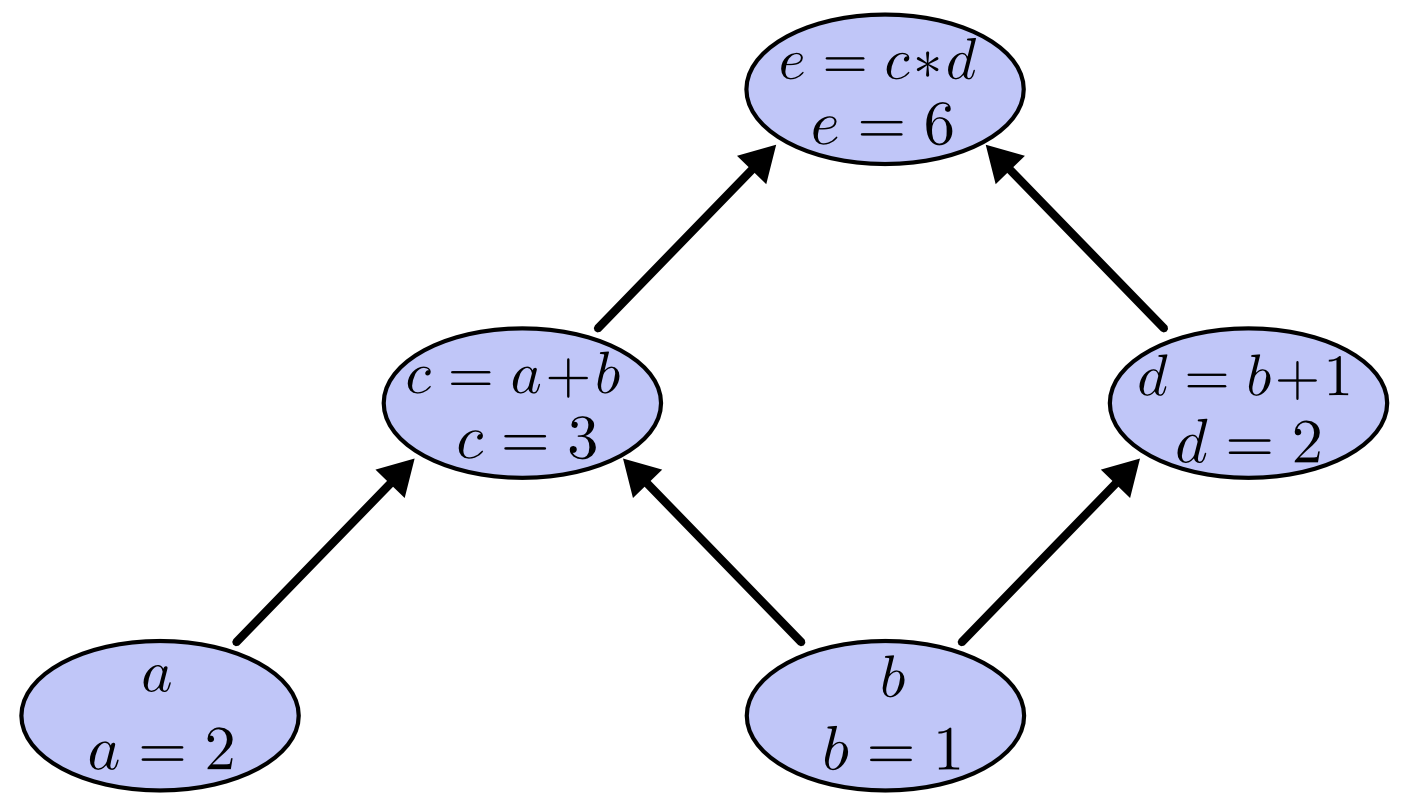
تمام اجزای این گراف برای تنسورفلو به طور کامل قابل بیان است. تا جایی که می تواند عملیات بهینه سازی مبتنی بر مشتق (مثل گرادیان نزولی) را بر روی یک گراف انجام دهد. به طور کلی مشتق گیری برروی گراف های محاسباتی از قوانین ساده ای پیروی می کند. برای شکل بالا اعمال این قواعد به شکل زیر خواهد شد:
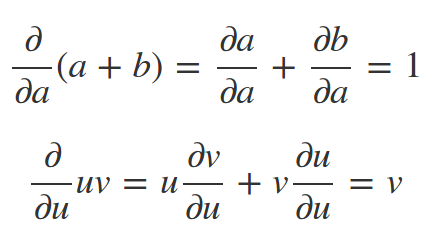
در شکل زیر هم مسیر مشتق گیری بر روی گراف محاسباتی نشان داده شده است:
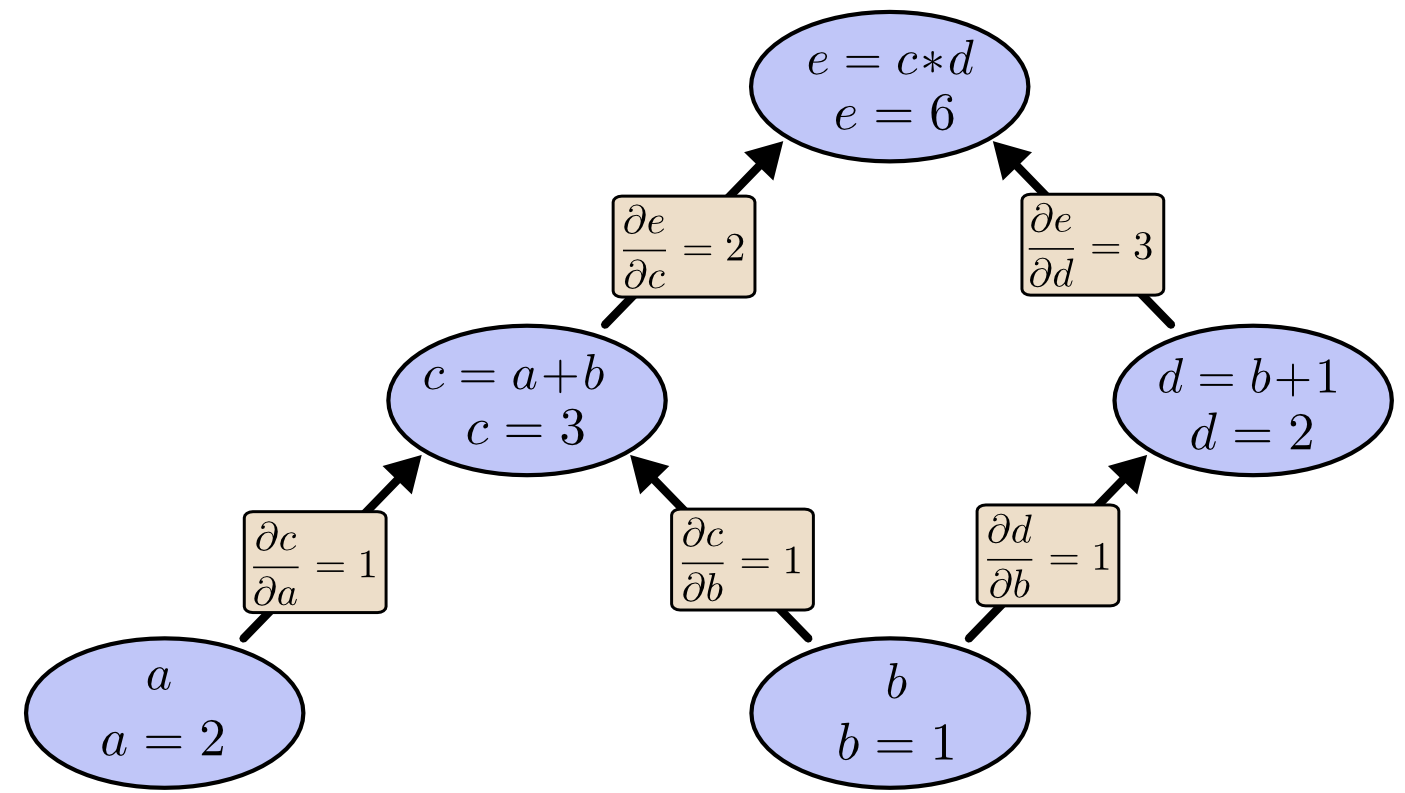
به طور کلی دو قانون ساده برای مشتق گیری بر روی گراف محاسباتی وجود دارد.
۱- مشتق های موازی با هم جمع میشوند
۲- مشتق های سری در هم ضرب می شوند.
مثلا در شکل زیر:
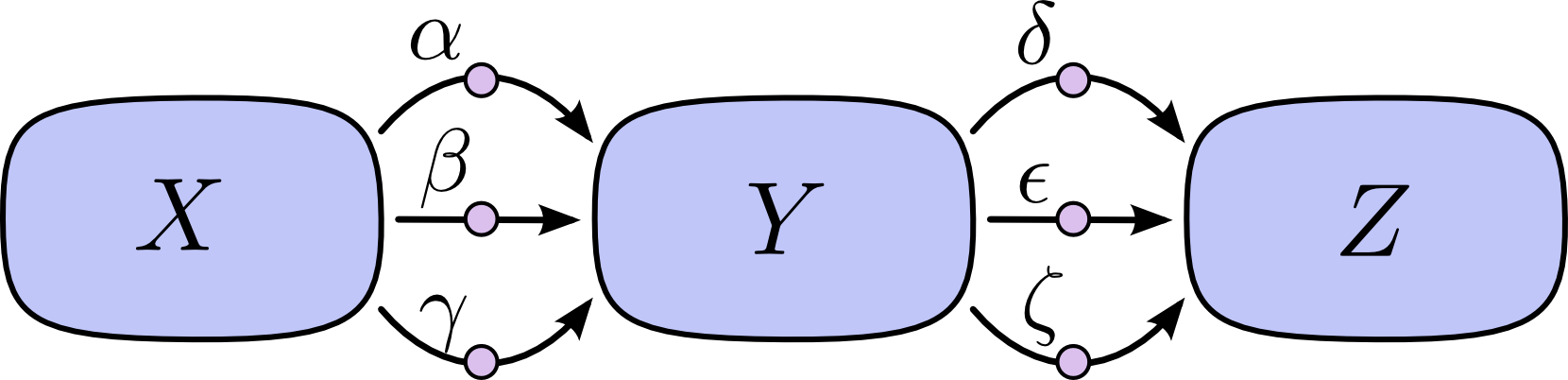
مشتق به صورت زیر در می آید:
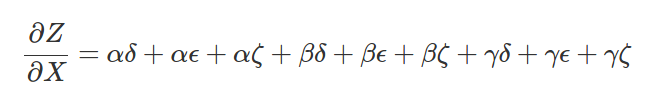
تیانو و تنسورفلو(که تماما شبیه به تیانو است) از همین دو اصل ساده برای بهینه سازی و آموزش شبکه عصبی استفاده می کنند. در حقیقت محاسبه ی مشتق توابع تودرتو هنر اصلی تنسورفلو و تیانو است. برای محاسبه دو تابع تودرتوی سهمی در هر نقطه ی دلخواه تکه کد زیر کافی است.
import tensorflow as tf
def get_gradient(fx):
opt = tf.train.GradientDescentOptimizer(0.1)
grads = opt.compute_gradients(fx)
sess = tf.Session()
sess.run(tf.initialize_all_variables())
grad_vals = sess.run([grad[0] for grad in grads])
return grad_vals
point = 3.0
x = tf.Variable(float(point))
g_x = x * x
fog_x = g_x * g_x
print(get_gradient(fog_x))
# [108.0]
البته به طور کلی نیازی به محاسبه ی مشتق و محاسبه ی دستی گرادیان نزولی نیست. چون کلاس هایی مثل GradientDescentOptimizer و AdamOptimizer و... عملیات بهینه سازی را برای ما انجام می دهند. برای شروع با یکی از این بهینه سازها یک مساله ی رگرسیون خطی را حل میکنیم که نمودار داده ها و تابع تولید کننده ی آن به صورت زیر است:
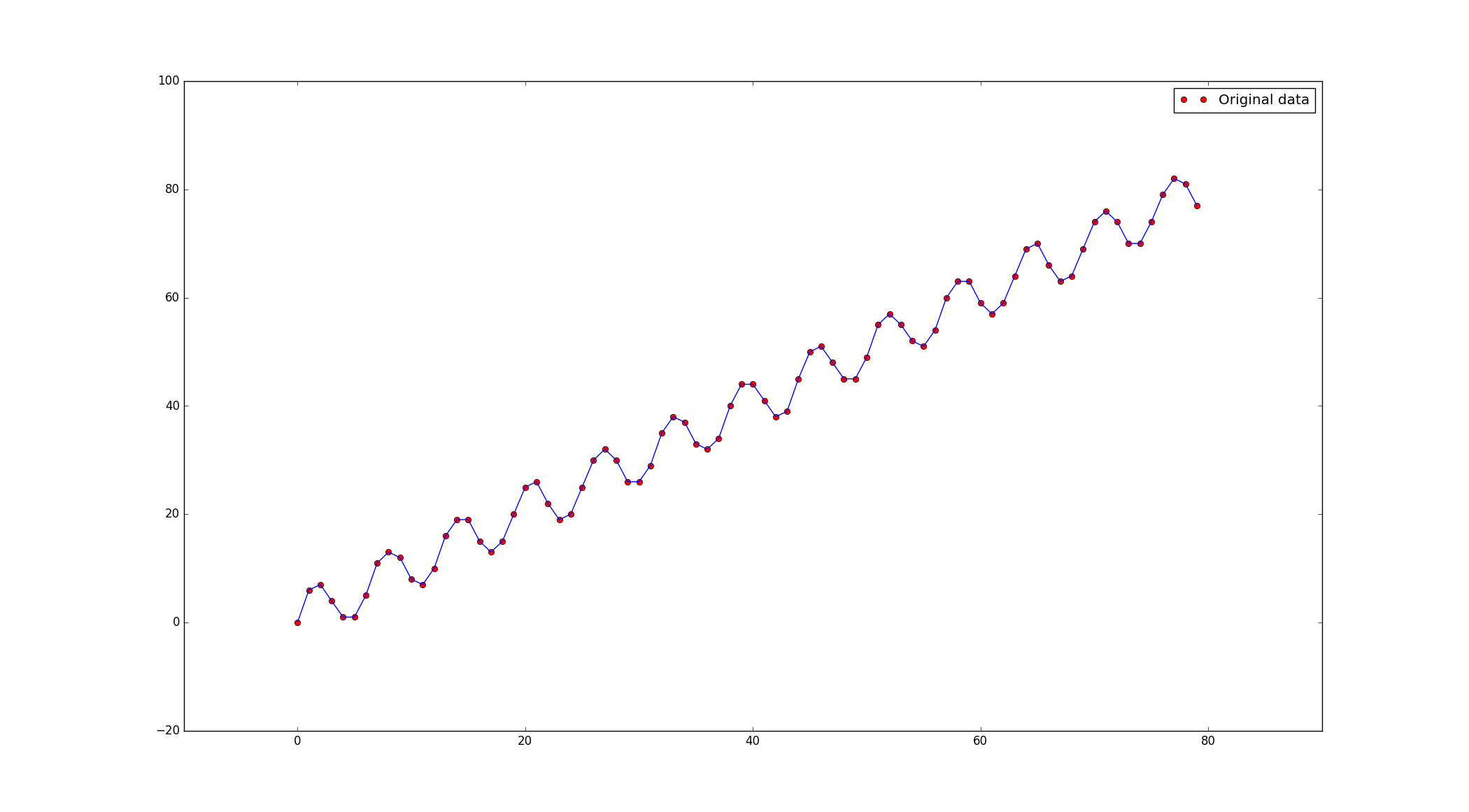
def data_maker(num=80):
X = np.arange(0, num, dtype=np.float32)
Y = np.float32(np.ceil(5 * (np.sin(X) + X / 5)))
return X, Y
کد کامل را میتوانید از گیت هاب دریافت کنید.
ما در تابع fit عملیات یادگیری را انجام می دهیم:
def fit(self):
x = tf.placeholder("float")
y = tf.placeholder("float")
a = tf.Variable(1.0, name="weight")
b = tf.Variable(1.0, name="bias")
pred = tf.mul(x, a) + b
cost = tf.reduce_mean(tf.abs(pred - y))
optimizer = tf.train.GradientDescentOptimizer(self.learning_rate).minimize(cost)
init = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
for epoch in range(self.training_epochs):
for i, out in zip(self.train_X, self.train_Y):
sess.run(optimizer, feed_dict={x: i, y: out})
print("Epoch:", '%04d' % (epoch + 1), "cost=", "W=", sess.run(a), "b=", sess.run(b))
print("Optimization Finished!")
training_cost = sess.run(cost, feed_dict={x: self.train_X, y: self.train_Y})
print("Training cost=", training_cost, "a=", sess.run(a), "b=", sess.run(b), '\n')
return sess.run(a), sess.run(b)
در پست آینده در مورد اجزای این تکه کد صحبت خواهیم کرد.
منبع تصاویر: colah.github.io
